
在上一篇文章中,我們深入探討了 LLM 應用的獨特性。它是一個機率性的、以語義為核心的「黑盒子」。我們意識到,傳統的監控手段已無法應對其在遙測、輸出、成敗判斷和成本模型上的全新挑戰。文章的結尾,我們將希望寄託於一個統一的標準:OpenTelemetry。
當今可觀測性領域正處於關鍵時刻,雖然我們的應用程式產生的遙測資料比以往任何時候都多,但這些豐富的資訊通常分散在不同的孤島工具中,日誌、指標和追蹤資料各自獨立。同時,生成式AI 正如一顆即將撞擊產業的巨型小行星,迅猛而至。


無論你使用的是 OpenAI、Google Gemini 還是開源的 Llama 模型,無論你的應用是基於 LangChain 還是自研框架,OpenTelemetry 都提供了一套統一的 API 和 SDK。這意味著你的開發團隊可以用同樣的方式來進行埋點 (instrumentation),而無需為每個不同的 LLM 供應商或框架學習新的工具,極大地降低了接入成本。
到目前為止,官方依然積極的更新 Instrumentation Library:https://github.com/open-telemetry/opentelemetry-python-contrib/tree/main/instrumentation-genai
這是 OpenTelemetry 在 LLM 領域最核心的貢獻,它為跨平台遙測資料的建構和收集方式建立了標準化指南,定義了輸入、輸出和操作細節。
對於生成式 AI,這些約定透過標準化模型參數、回應 metadata 和 token 使用等屬性,簡化了 AI 模型的監控、故障排除和最佳化。這種一致性支援跨工具、環境和 API 實現更佳的可觀察性,幫助組織輕鬆追蹤效能、成本和安全性。
例如,當你發起一次 LLM 呼叫時,OpenTelemetry 的 Span 中會包含如下標準屬性:
gen_ai.system: 使用的系統,如 "openai", "bedrock"。gen_ai.request.model: 呼叫的具體模型,如 "gpt-4-turbo"。gen_ai.usage.input_tokens: 輸入的 Prompt 消耗了多少 Token。gen_ai.usage.output_tokens: 輸出的 Response 消耗了多少 Token。gen_ai.response.finish_reasons: 模型結束回應的原因,如 "stop", "tool_calls"。這套「通用格式」確保了無論數據來自哪個模型,我們都能用同樣的方式進行查詢、聚合與分析。你可以輕易地比較不同模型的 Token 消耗和成本,而無需做任何數據轉換。
OpenTelemetry GenAI Semantic Conventions 也為 OpenAI 和 Azure 推理 API 等平台定義了特定於供應商的屬性,確保遙測資料能夠擷取通用資訊和特定於提供者的詳細資訊。https://opentelemetry.io/docs/specs/semconv/gen-ai/
一個看似簡單的 LLM 應用,其背後可能是一個複雜的 Agent 或 RAG (Retrieval-Augmented Generation) 流程。它可能包含多個步驟:解析使用者問題、呼叫向量資料庫、多輪 LLM 推理、呼叫外部工具 (Tool Calling) 等。
OpenTelemetry 的分散式追蹤能力可以將這整個鏈路串連成一個完整的 Trace。開發者可以清晰地看到從最初的 Prompt 輸入,到中間每一個步驟的耗時、輸入輸出,直到最終 Response 生成的全過程。這對於除錯複雜的 AI Agent 流程、定位效能瓶頸至關重要。
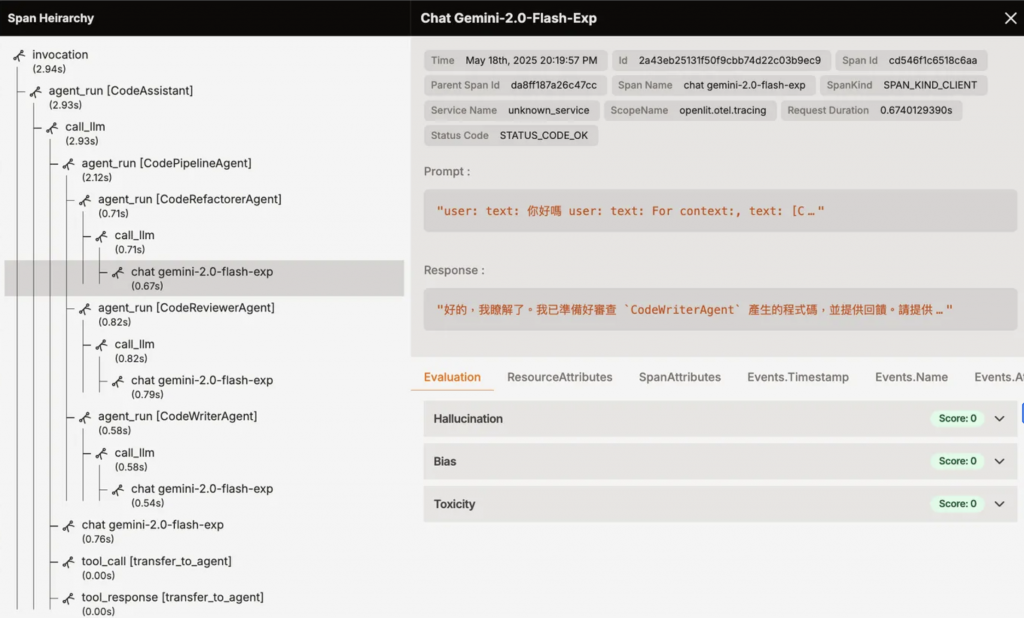
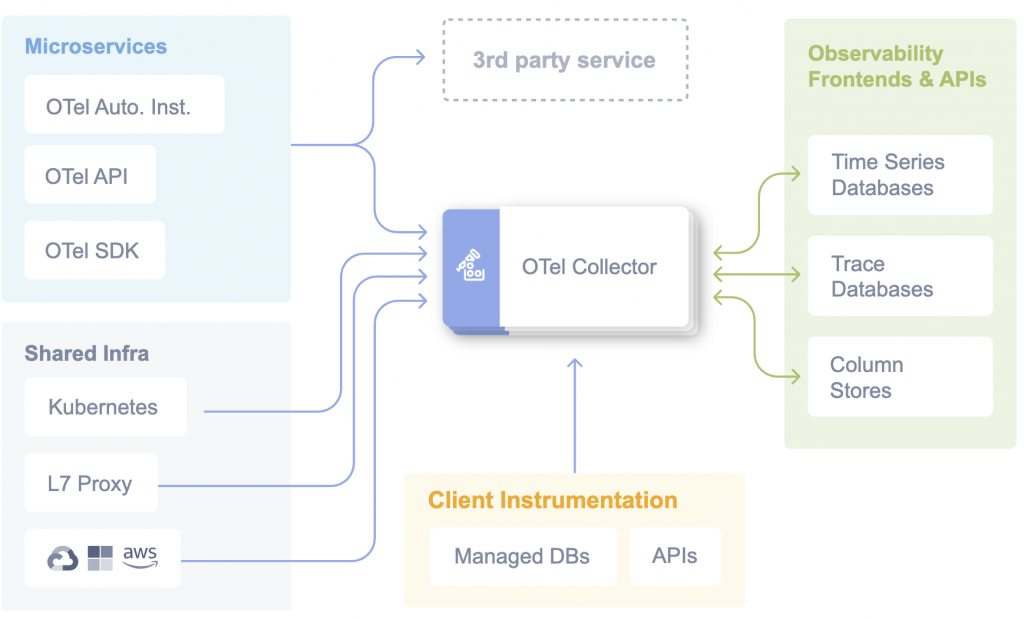
得益於 OpenTelemetry 的統一標準,已經建立在此基礎上的 LLM 遙測指標都能與 Grafana、Datadog、New Relic 等主流可觀測性平台即插即用。從儀表板、告警、故障診斷到品質追蹤,都可沿用既有的可觀測性堆疊,降低導入與維運成本。即使我們在進階場景中也額外搭建 LLM 可觀性平台,但對於 LLM 應用的整合與持續優化來說,這必然是一塊不可或缺的拼圖。
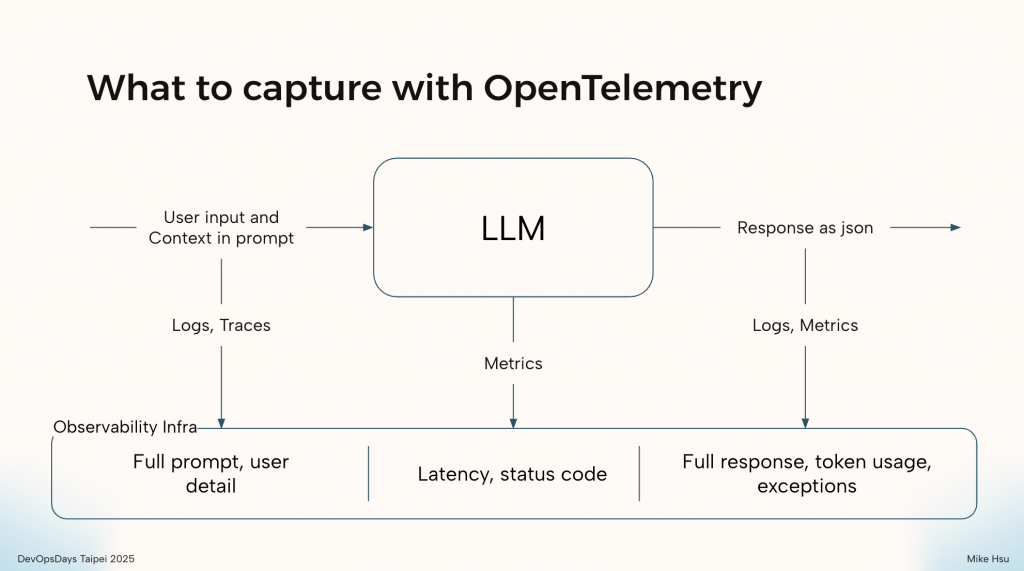
我們可以將任何一次與 LLM 的互動解構成三個核心部分:輸入 (Input)、過程 (Process)、與輸出 (Output)。這三者共同構成了一個完整的、可供分析的事件。
如上圖所示,OpenTelemetry 讓我們能針對這三個部分,系統性地收集對應的遙測訊號:
這是所有分析的起點。使用者輸入了什麼?我們在背景中為他添加了哪些上下文 (Context) 或 RAG 的檢索結果?這些資訊至關重要。
這是指 LLM 模型本身在處理請求時的狀態,更接近傳統可觀測性的範疇。
這是 LLM 互動的結果,也是我們進行評估和成本分析的依據。
透過將 Logs、Traces、Metrics 這三大訊號巧妙地應用在 LLM 互動的這三個階段,OpenTelemetry 幫助我們為每一次黑盒子般的 AI 對話,都建立了一份 360 度的完整檔案。有了這份檔案,後續的除錯、評估與優化才有了堅實的數據基礎。

理論上我們知道了要收集輸入、過程、輸出的數據,但一進入真實的開發場景,新的問題立刻浮現。
看看上面這個範例,右側的流程圖展示了一個看似簡單的問答背後,可能隱藏著多個函式之間的複雜互動:模型可能需要呼叫外部工具 (Tool Calling) 來獲取即時天氣,再將結果整合進最終的回應。
正因為流程如此複雜,我們才需要有意識地記錄每個環節。但問題來了:
到底哪些資訊是真的有價值、一定要留下來,哪些其實只是雜訊?
在多團隊協作時,這個問題會被放大。A 團隊可能把模型名稱記為 model_name,B 團隊卻用 llm.model;有人關心 top_p 參數,有人卻只記錄 temperature。如果沒有統一的標準,我們收集到的遙測數據最終只會變成一座難以分析、無法共通的數據孤島。
幸好,這些問題,OpenTelemetry 都幫我們設想好了。
它最核心的價值之一,就是提供了一套嚴謹且全面的 GenAI 語義約定 (Semantic Conventions)。這套約定詳細定義了在 LLM 應用中,每個關鍵屬性應該如何命名、記錄什麼內容,確保了全球開發者都能「說同一種語言」。
讓我們看看圖片左側的範例,這是一個真實 Trace Span 可能包含的部分屬性:
gen_ai.system: "openai"gen_ai.request.model: "gpt-4"gen_ai.request.max_tokens: 200gen_ai.usage.input_tokens: 47gen_ai.usage.output_tokens: 17gen_ai.response.finish_reasons: ["tool_calls"]從模型系統、請求參數,到精確的 Token 計數和結束原因,這些標準化的欄位就像一份詳細的「請求履歷」。它讓我們能精準地還原每一次請求到底發生了什麼事,而不用去猜測每個欄位的真實含義。
當我們真正開始遵循這套標準來收集數據後,往往會驚訝地發現:原來過去忽略了這麼多有價值的細節。而正是這些看似繁瑣的標準化數據,最終會成為我們進行模型評估、成本優化和線上問題診斷時,最可靠的依據。
有了 OpenTelemetry 這個強大的武器,我們似乎已經萬事俱備,但在真實的企業環境中,將理論付諸實踐,實務上還需要克服許多常見的挑戰,如以下:
即使在 AI 最盛行的時代中,想把一件事情做好依然沒有太多捷徑,我們可以看出 LLM 可觀測性並非即插即用。它需要架構上的前瞻性、營運上的嚴謹性、以及團隊間的協調一致。然而,如果使用得當,它將成為隱形的基礎設施,來確保我們的生成式 AI 系統在生產環境中保持高效能、可預測性的可靠度。

